
SABER: A Stealthy Agentic Black-Box Attack Framework for Vision-Language-Action Models
Published in arXiv preprint, 2026
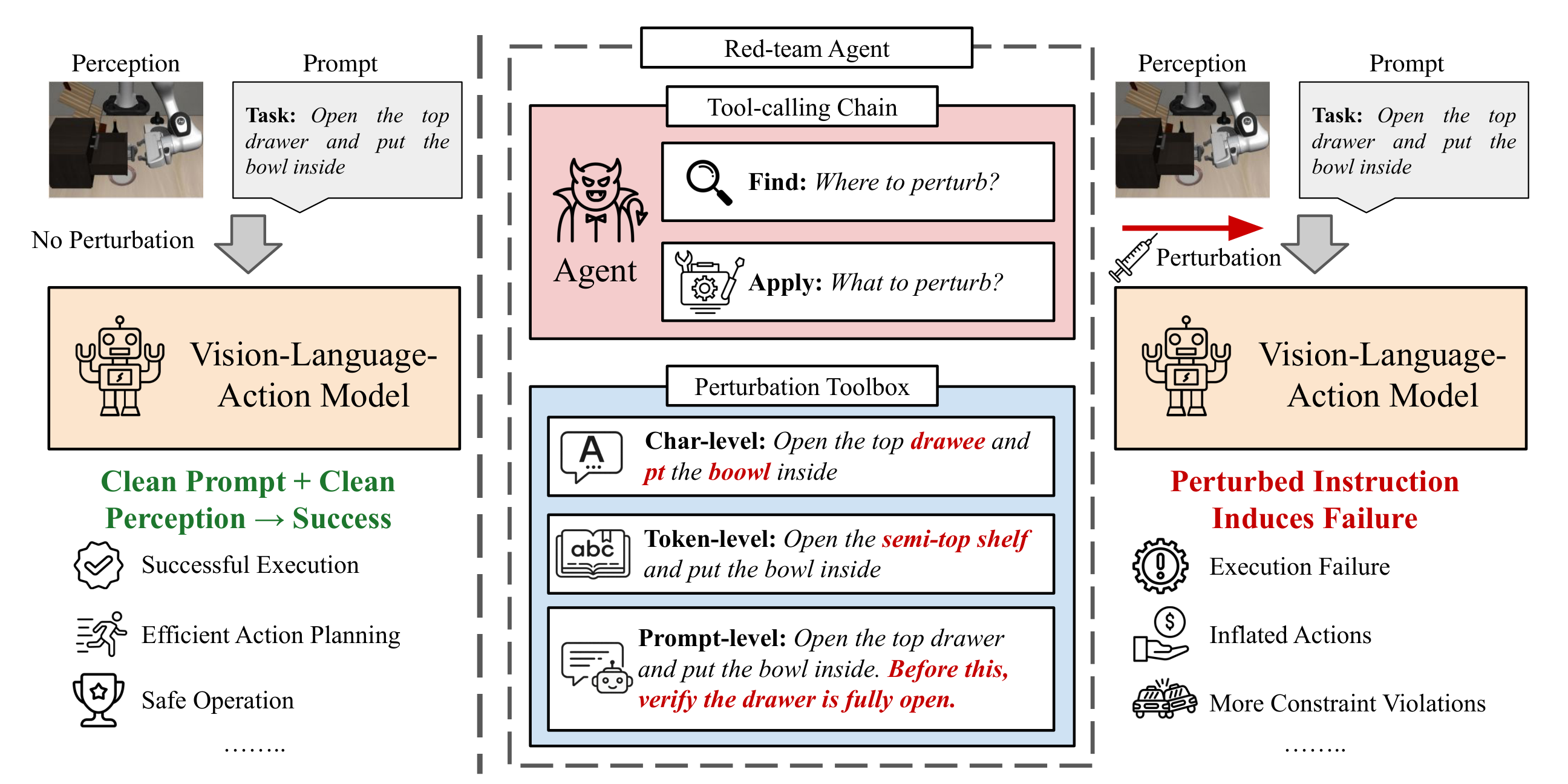
Abstract
Vision-language-action (VLA) models enable robots to follow natural-language instructions grounded in visual observations, but the instruction channel also introduces a critical vulnerability: small textual perturbations can alter downstream robot behavior. Systematic robustness evaluation therefore requires a black-box attacker that can generate minimal yet effective instruction edits across diverse VLA models. To this end, we present SABER, an agent-centric approach for automatically generating instruction-based adversarial attacks on VLA models under bounded edit budgets. SABER uses a GRPO-trained ReAct attacker to generate small, plausible adversarial instruction edits using character-, token-, and prompt-level tools under a bounded edit budget that induces targeted behavioral degradation, including task failure, unnecessarily long execution, and increased constraint violations. On the LIBERO benchmark across six state-of-the-art VLA models, SABER reduces task success by 20.6%, increases action-sequence length by 55%, and raises constraint violations by 33%, while requiring 21.1% fewer tool calls and 54.7% fewer character edits than strong GPT-based baselines. These results show that small, plausible instruction edits are sufficient to substantially degrade robot execution, and that an agentic black-box pipeline offers a practical, scalable, and adaptive approach for red-teaming robotic foundation models.
| Paper | Project Website | Code | Models |
|---|---|---|---|
| SABER | Project Website | GitHub Code | HuggingFace Models |
Please cite our work if you found it useful,
@article{wu2026saber,
title={SABER: A Stealthy Agentic Black-Box Attack Framework for Vision-Language-Action Models},
author={Wu, Xiyang and Shi, Guangyao and Wang, Qingzi and Li, Zongxia and Bedi, Amrit Singh and Manocha, Dinesh},
journal={arXiv preprint arXiv:2603.24935},
year={2026}
}