
COS-PLAY: Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
Published in arXiv preprint, 2026
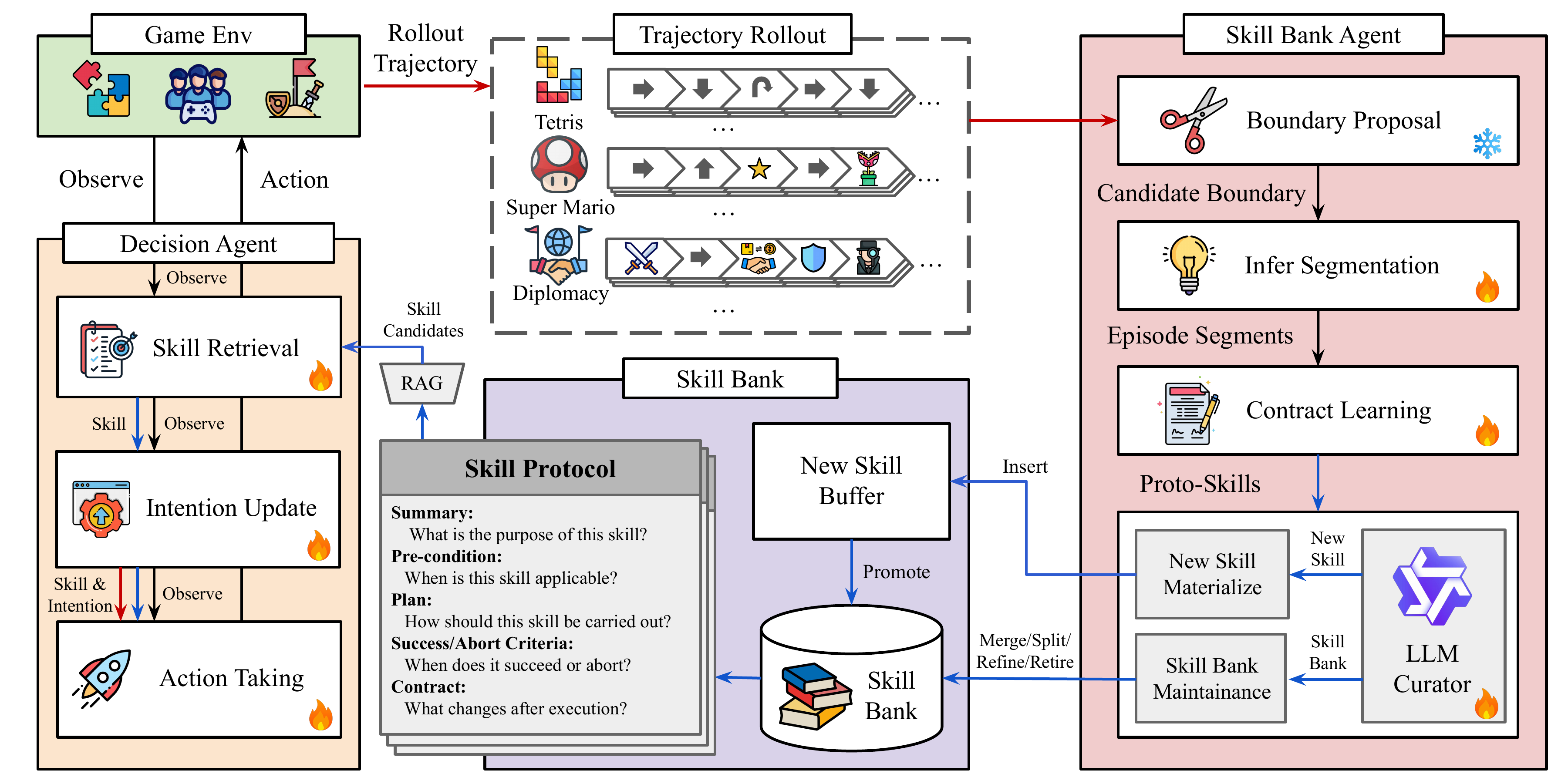
Abstract
Long-horizon interactive environments demand multi-step reasoning, the chaining of multiple skills over many timesteps, and robust decision-making under delayed rewards and partial observability. Large Language Models (LLMs) offer a promising alternative as game-playing agents, but they often struggle with consistent long-horizon decision-making because they lack a mechanism to discover, retain, and reuse structured skills across episodes. We present COS-PLAY, a co-evolution framework in which an LLM decision agent retrieves skills from a learnable skill bank to guide action taking, while an agent-managed skill pipeline discovers reusable skills from the agent's unlabeled rollouts to form a skill bank. Our framework improves both the decision agent to learn better skill retrieval and action generation, while the skill-bank agent continually extracts, refines, and updates skills together with their contracts. Experiments across six game environments show that COS-PLAY with an 8B base model achieves over 25.1% average reward improvement against four frontier LLM baselines on single-player game benchmarks while remaining competitive on multi-player social reasoning games.
| Paper | Project Website | Code | Models | Cold-Start Data |
|---|---|---|---|---|
| COS-PLAY | Project Website | GitHub Code | HuggingFace Models | Cold-Start Data |
Please cite our work if you found it useful,
@misc{wu2026coevolvingllmdecisionskill,
title={Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks},
author={Xiyang Wu and Zongxia Li and Guangyao Shi and Alexander Duffy and Tyler Marques and Matthew Lyle Olson and Tianyi Zhou and Dinesh Manocha},
year={2026},
eprint={2604.20987},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2604.20987},
}